
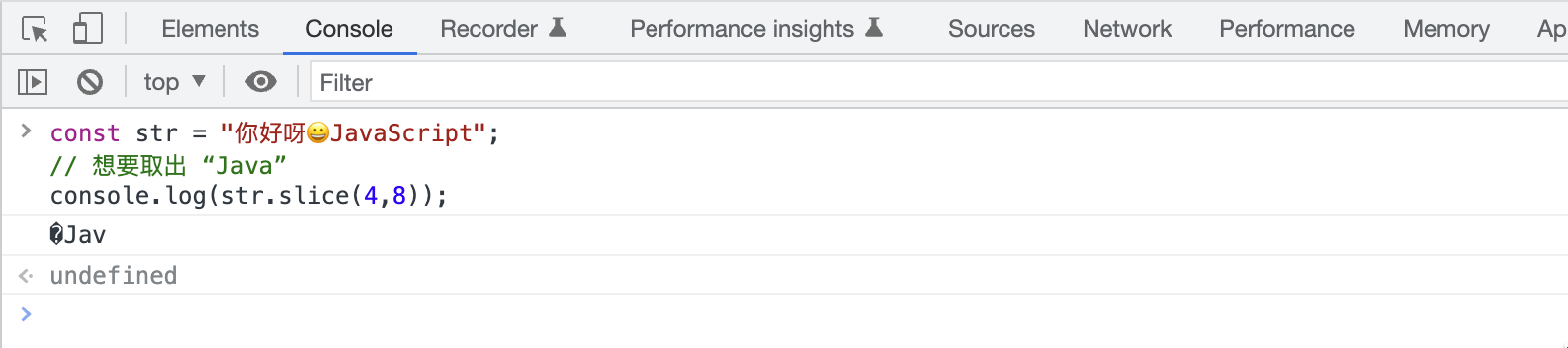
我们知道 js 中的 String.prototype.slice() 方法可提取字符串的某个部分,并以新的字符串返回被提取的部分。但是下面这段代码就会有一些问题:
const str = "你好呀😀JavaScript";
// 想要取出 “Java”
console.log(str.slice(4,8));
但是打印的结果却是:�Jav
 为什么会出现这个问题呢?
因为在很早的时候,JS 对字符的编码采用的编码规范是 ucs-2,这种规范规定每一个文字对应16位的空间,然后把这16位的空间成为码元。即一个文字对应一个码元。但是后来随着生僻字越来越多,还加入了一些 emoji 表情,16位的空间已经不够用了,于是 JS 把编码方式换成了 utf-16。utf-16 允许一个文字占用16位的空间,也可以运行一些文字占用32位的空间。而我们在 js 中使用的
为什么会出现这个问题呢?
因为在很早的时候,JS 对字符的编码采用的编码规范是 ucs-2,这种规范规定每一个文字对应16位的空间,然后把这16位的空间成为码元。即一个文字对应一个码元。但是后来随着生僻字越来越多,还加入了一些 emoji 表情,16位的空间已经不够用了,于是 JS 把编码方式换成了 utf-16。utf-16 允许一个文字占用16位的空间,也可以运行一些文字占用32位的空间。而我们在 js 中使用的 length 属性实际上数的是码元的数量。
比如上面那段字符串,使用 length 属性取到的长度是 15。
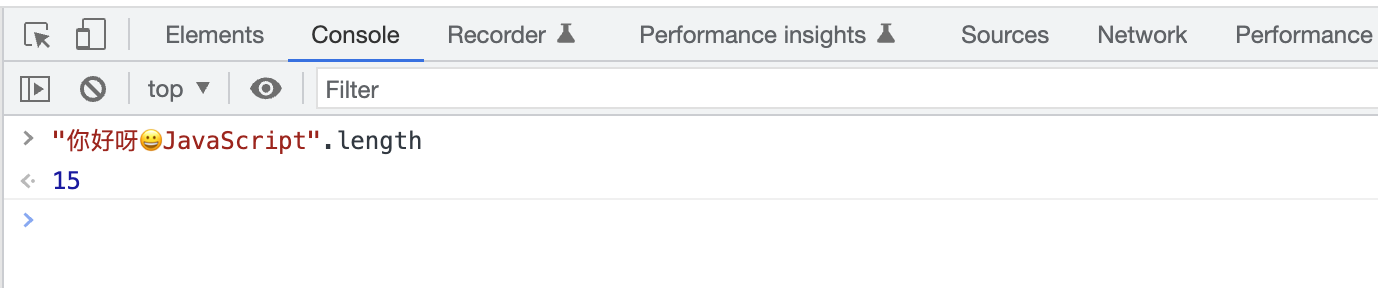 是因为 enmoji 占用了两个码元的位置。
是因为 enmoji 占用了两个码元的位置。
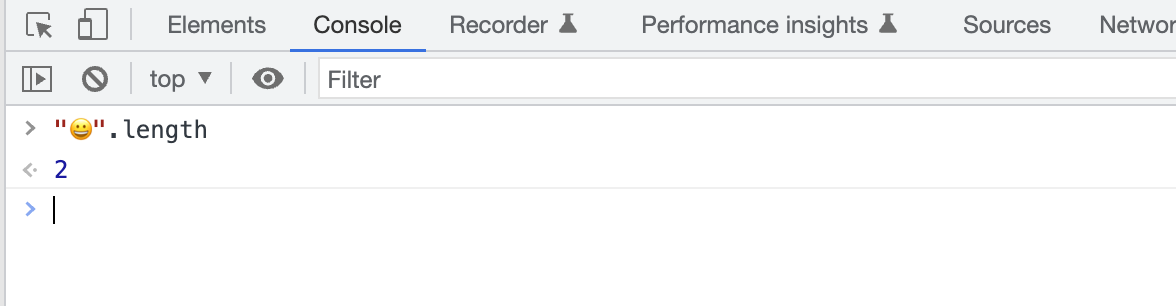 同样字符后面跟中括号取下标,也是指码元的下标。
回到上面的问题,到底怎么截取字符串才能满足我们的需求呢,我们可以自己写一个 sliceByPoint 的方法。在这个方法的实现中,需要用到两个方法:
同样字符后面跟中括号取下标,也是指码元的下标。
回到上面的问题,到底怎么截取字符串才能满足我们的需求呢,我们可以自己写一个 sliceByPoint 的方法。在这个方法的实现中,需要用到两个方法:
String.prototype.codePointAt()返回一个 Unicode 编码点值的非负整数。String.fromCodePoint()返回使用指定的代码点序列创建的字符串。
具体方法实现:
function sliceByPoint(str, pStart, pEnd) {
let result = ""; // 截取的结果
let pIndex = 0; // 码点的指针
let cIndex = 0; // 码元的指针
while (1) {
// 结束条件:码点的指针到达指定位置 || 码元的指针到达数组的最后
if (pIndex >= pEnd || cIndex >= str.length) {
break;
}
const point = str.codePointAt(cIndex); // 码点
if (pIndex >= pStart) {
result += String.fromCodePoint(point); // 按照码点来恢复文字
}
pIndex++;
cIndex += point > 0xffff ? 2 : 1;
}
return result;
}
不过还可以有更简单的实现方式,使用 es6 提供的 Array.from 处理
function sliceByPoint(str, pStart, pEnd) {
return Array.from(str).slice(pStart, pEnd).join('');
}